[Проблема] Парсинг больших страниц регулярным выражением
-
Я получаю несколько страниц через http клиент, потом нахожу в них ссылки на другие страницы по определённому регулярному выражению. В итоге на самой последней странице находятся не все ссылки, а только очень маленькая их часть (до 5 штук максимум, хотя их должно быть до 30).
На самой последней странице мне необходимо найти ссылки только с блока, где есть слово ПЗСО.
Вот прикрепляю свой скрипт.
0_1501525839309_Parser_0.0.5.xmlЯ также заметил, что регулярные выражения хорошо работают на страницах размером 23 00 или 50 000 байт, но когда дело касается больших страниц - до 300 000 байт начинаются глюки.
-
Вот наглядный пример. Вот сайт - http://vstup.info/2017/i2017i217.html
Через Get запрос получаю его код.
И пытаюсь регуляркой получить все ссылки из блоков, где есть слово ПЗСО.Регулярка вот - " >ПЗСО<+.href="./(.).html">.* "
Мне выдаёт только один ответ - "217/i2017i217p416634". Кстати, возможно это важно! Я получаю только каталог и код специально, мне оно не нужно с расширением .html в дальнейшем
Ну а как же например - "217/i2017i217p393297.html"!?
Вот этот тестовый проект по проще:
0_1501527120859_BASPR1.xmlUPD. Даже когда я пытаюсь найти все ссылки на этой странице, то их количество равно всего 3.
Вот этот проект:
0_1501528480390_BASPR1.xmlВ первом примере города и названия вузов получаются все без исключения, но специальности почему-то не находятся полностью
-
Без обид, но для начала неплохо бы подучить регулярки.
-
@D1MA12 У тебя регулярка
>ПЗСО<+.*href="\.\/(.*)\.html">.*вконце стоит.означающие любой символ, и*означает от нуля и до последнего любого символа. То есть он находит первое совпадение и собирает весь оставшийся файл в ответ.
-
@D1MA12 Самая элементарная регулярка
>ПЗСО<.*?href="\.\/(.*?)\.html">спокойно находит 42 совпадения.
Вот тут смотри. Вообще советую испытывать все свои регулярки на сайте https://regex101.com
-
Да, регулярки я осваивал исключительно на BASе и делал всё методом тыка. Но тогда почему
.*href="/2017/(.*)\.html".*собирает все данные на своей странице, а
>ПЗСО<+.*href="\.\/(.*)\.html">.*нет?
@Fox Пока писал, вы написали ответ. Спасибо, буду изучать ваш код.
-
@D1MA12 Вот хорошая шпаргалка.
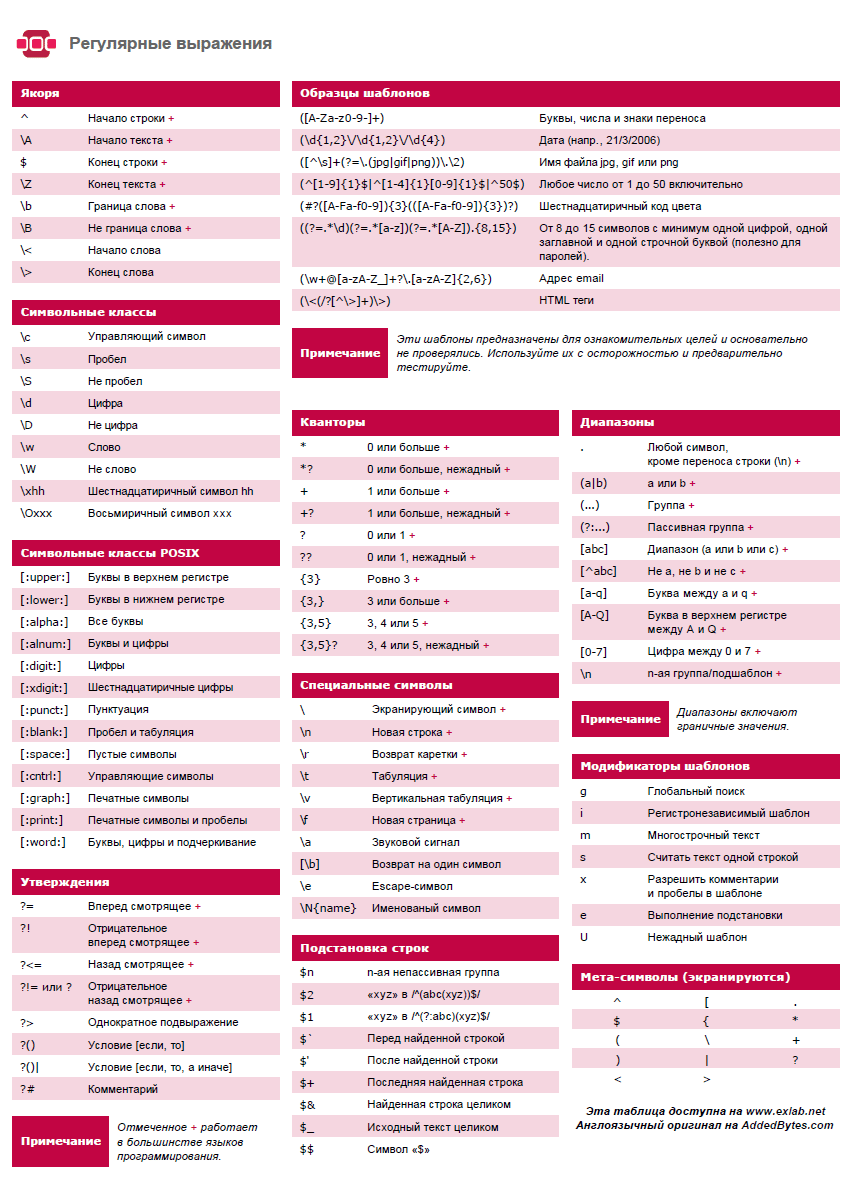
-
@D1MA12 лучше пользоваться xpath для парсинга html, если данные хорошо организованы
-
@DrPrime Та мне с одним способом добывания данных разобраться бы. А потом можно и разные вариации учить.
Спасибо большое всем за советы, особенно @Fox за предоставленный код и шпаргалку.


